
When new and popular trends emerge, buzzwords surface along with it. Such is the case for big data. Often used together with other concepts such as data science and machine learning, it can be rather confusing and daunting to step into.
A little history of data collection
As far back as 18,000 BCE, humans have been storing and analysing data using sticks. Palaeolithic tribespeople would make marks into sticks or bones to keep track of trading activity or supplies. This allowed them to calculate and predict how long their food supplies would last.
Humans later discovered paper and recorded their findings and analysis on scrolls and books. As technology advanced, other mediums such as tapes and data centers emerged.
With the introduction of the World Wide Web in 1991, everything changed. It is a worldwide, interconnected web of data which is accessible to anyone, anywhere. This led to the surge of data that we see today.
Recent advancements in technology such as cheaper chip and storage, Internet of Things and cloud computing are factors which will further lead to a surge in the quantities of data that is stored and analysed.
What is Big Data?
Big data refers to the large (think Terabytes) amounts of data that is stored in increasingly high tech systems servers. This could be from internal sources within the company and external sources from customers when they purchase a product or from suppliers when an order is made.
Data can be in the form of structured data – customer purchase data or payments information, or unstructured data – Internet search queries or pictures. All data, structured or unstructured, would eventually have to be converted into a structured format to be analysed.
Benefits of big data
Big data can be used for better customer targeting. By knowing the preferences and lifestyle of consumers as well as latest trends, companies are able to better predict what products to sell, when to sell and even the target group to market to.
By analysing the stage where customers drop-out in a page, companies can increase and optimise their sales funnel conversion rates. For example, if a customer signs up on an e-commerce site and has been browsing every day for shoes, all it may take could be an email to push the customer to complete the purchase.
The Technology
Now that we have covered the background and benefits of big data, let’s get down to the technology bit. Hadoop, Hive, Pig, Cloudera, Hortonworks, MapReduce, HDFS – what are all these words that are often mentioned by technology professionals?
First, Hadoop is an open-source (think free) software framework that allows large amounts of data to be stored and computed across clusters of computers. It is designed to scale from one computer to up to thousands of servers.
Cloudera and Hortonworks are vendors offering the Hadoop software, training, support and services to business customers. These could be offered either directly or via third party service providers.
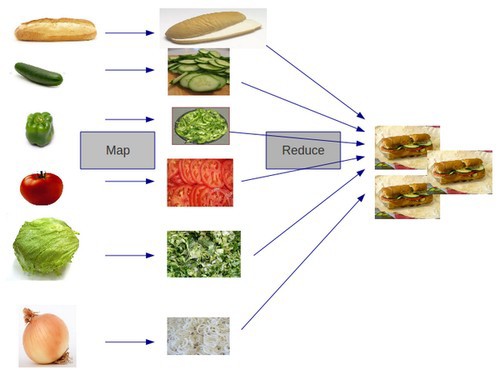
MapReduce is the programming model that is used to process and generate big data across a cluster in parallel. I particularly like the sandwich analogy to explain this concept. First, the ingredients are all chopped (akin to mapped) separately and in parallel. Once done, the ingredients are combined (or reduced) into the final sandwiches.
HDFS (of Hadoop File Storage) is the underlying file storage system of Hadoop. It provides scalable and reliable file storage. Combined with YARN (Yet Another Resource Network) – a resource management framework, this allows multiple data processes (interactive SQL, batch processing, real-time streaming, etc.) to handle the data stored.
Pig, Hive and Impala are just a few of the many big data tools used to access, manipulate, transform and analyse complex data sets.
An article on big data is of course not complete without the argument of Hadoop versus Spark. Spark is a data processing tool that operates on distributed data collections. Whereas Hadoop provides both distributed storage and processing, Spark only provides the latter. In fact, Spark is more similar to the MapReduce processing component used in Hadoop.
Listed above are just some of the more common technologies and words used by technology professionals. The Hadoop framework contains many other components and third-party connectors.
Summary
I hope that this article gives you a better understanding on the background and benefits of big data, as well as simplify some of the technical concepts and jargon used.
With a properly designed architecture and processing tools, data science teams can better analyse the deliver the benefits that we all yearn for.

One Reply to “Big Data Explained”